![]()
Home Week-2 Week-4
PDSA - Week 3
PDSA - Week 3Quick SortAlgorithm:VisualizationImplementationAnalysisComparison of sorting algorithmLinked ListVisualization of Linked ListImplementation of singly linked list in PythonStackBasic operations on StackApplications of StackImplementation of the Stack in PythonQueueBasic operations on QueueApplications of QueueImplementation of the Queue in pythonHash mappingCollisionCollision resolving techniqueOpen addressing(Close hashing)Closed addressing ( Open hashing)Visualization of Hashing
Quick Sort
Quick sort is a sorting algorithm that uses the divide-and-conquer strategy to sort the list of elements. The basic idea of quick sort is to partition the input list into two sub-list, one containing elements that are smaller than a chosen pivot element, and the other containing elements that are greater than or equal to the pivot. This process is repeated recursively on each sub-list until the entire list is sorted.
Algorithm:
Choose a pivot element from the list. This can be any element, but typically the first or last element is chosen.
Partition the list into two sub-list, one containing elements smaller than the pivot, and the other containing elements greater than or equal to the pivot. Steps for Partition:-
Set pivot to the value of the element at the lower index of the list L.
Initialize two indices i and j to lower and lower+1 respectively.
Loop over the range from lower+1 to upper (inclusive) using the variable j.
If the value at index j is less than or equal to the pivot value, increment i and swap the values at indices i and j in the list L.
After the loop, swap the pivot value at index lower with the value at index i in the list L.
Return the index i as the position of the pivot value.
Recursively apply steps 1 and 2 to each sub-list until the entire list is sorted.
Visualization
Select the Quick Sort(QUI) option on top bar then run the visualization.
Source - https://visualgo.net/en/sorting
Implementation
x1def partition(L,lower,upper):2 # Select first element as a pivot 3 pivot = L[lower]4 i = lower5 for j in range(lower+1,upper+1):6 if L[j] <= pivot:7 i += 18 L[i],L[j] = L[j],L[i]9 L[lower],L[i]= L[i],L[lower]10 # Return the position of pivot11 return i12
13def quicksort(L,lower,upper):14 if(lower < upper):15 pivot_pos = partition(L,lower,upper);16 # Call the quick sort on leftside part of pivot17 quicksort(L,lower,pivot_pos-1)18 # Call the quick sort on rightside part of pivot19 quicksort(L,pivot_pos+1,upper)20 return L
Code Execution Flow
Lecture Implementation
xxxxxxxxxx211def quicksort(L,l,r): # Sort L[l:r]2 if (r - l <= 1):3 return L4 (pivot,lower,upper) = (L[l],l+1,l+1)5 for i in range(l+1,r):6 if L[i] > pivot:7 # Extend upper segment8 upper = upper+19 else:10 # Exchange L[i] with start of upper segment11 (L[i], L[lower]) = (L[lower], L[i])12 # Shift both segments13 (lower,upper) = (lower+1,upper+1)14 # Move pivot between lower and upper15 (L[l],L[lower-1]) = (L[lower-1],L[l])16 lower = lower-117 18 # Recursive calls19 quicksort(L,l,lower)20 quicksort(L,lower+1,upper)21 return(L)
Code Execution Flow
Analysis
Best Case - In each recursive call, If the selected pivot element comes at the middle position and divide the list into two equal halves.
Recurrence relation:-
Complexity:-
Worst Case - If the list is already sorted in ascending or descending order (if the selected pivot element comes at the first or last position of the list in each recursive call).
Recurrence relation:-
Complexity:-
Average Case
Complexity:-
Stable - No
Sort in Place - Yes
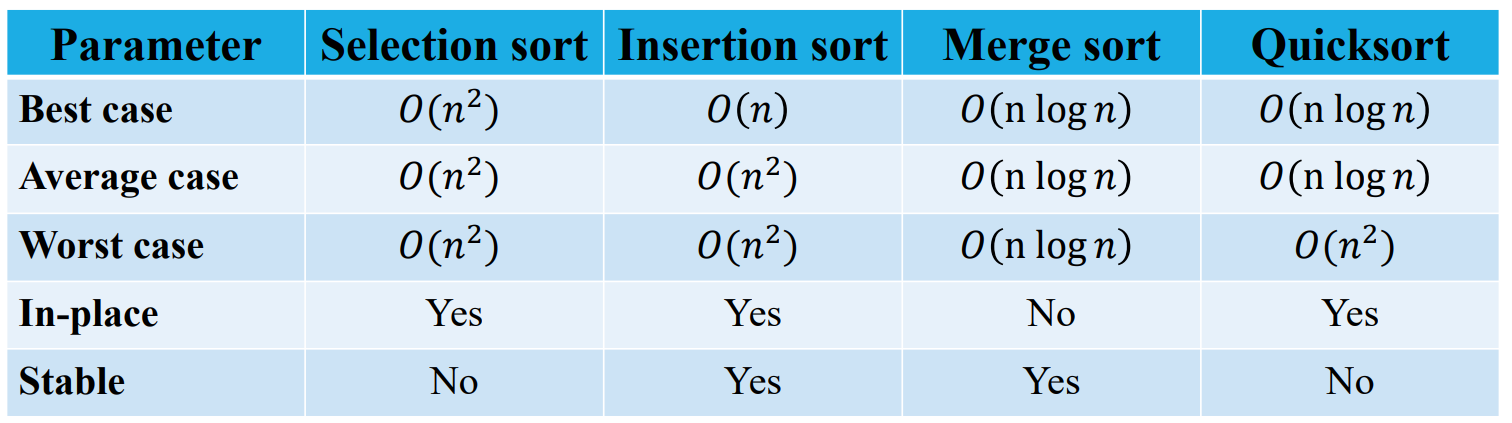
Comparison of sorting algorithm
Linked List
A linked list is a data structure consisting of a sequence of nodes, where each node contains a piece of data and a reference (or pointer) to the next node in the sequence. The first node is called the head, and the last node is called the tail, and the tail node points to null. Linked lists are useful for storing and manipulating collections of data, especially when the size of the collection is not known in advance, as they can dynamically adjust in size.
There are two types of linked lists:
Singly linked list
Doubly linked list
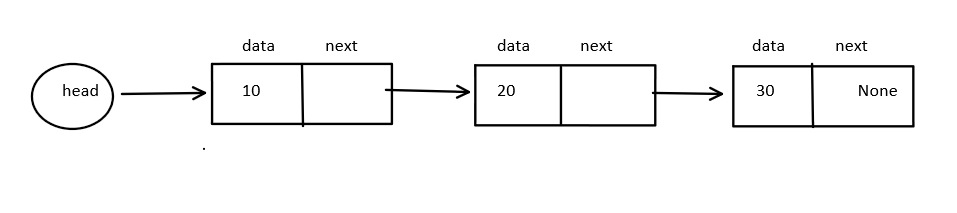
Singly linked list
head:- Store the reference of the first node. If the list is empty, then it storesNoneEach node have two fields:
data:- Store actual valuenext:- Store reference of the next node
Representation
Doubly linked list
head:- Store the reference of the first node. If the list is empty, then it storesNonetail:- Store the reference of the last node. If the list is empty, then it storesNoneEach node have three fields:
prev:- store reference of the previous nodedata:- Store actual valuenext:- Store reference of the next node
Representation

Visualization of Linked List
Select the Linked List(LL) or Doubly Lined List(DLL) option on top bar then run the visualization.
Source - https://visualgo.net/en/list
Implementation of singly linked list in Python
Using one class- Recursively
xxxxxxxxxx771class Node:2 def __init__(self, v = None):3 self.value = v4 self.next = None5 return6 def isempty(self):7 if self.value == None:8 return(True)9 else:10 return(False)11 # recursive12 def append(self,v):13 # If current node is empty14 if self.isempty(): 15 self.value = v16 # If current node is last node of the list 17 elif self.next == None:18 self.next = Node(v)19 # Else raverse to next node20 else:21 self.next.append(v) 22 return23 # append, iterative24 def appendi(self,v):25 # if current node is empty 26 if self.isempty():27 self.value = v28 return29 temp = self30 # Traverse the list to find the last node31 while temp.next != None:32 temp = temp.next33 temp.next = Node(v) 34 return35 def insert(self,v):36 if self.isempty():37 self.value = v38 return39 newnode = Node(v)40 # Exchange values in self and newnode41 (self.value, newnode.value) = (newnode.value, self.value)42 # Switch links43 (self.next, newnode.next) =(newnode, self.next)44 return45 # delete, recursive46 def delete(self,v):47 # If list is empty48 if self.isempty():49 return50 # If v is the current node of the list51 if self.value == v:52 self.value = None53 if self.next != None:54 self.value = self.next.value55 self.next = self.next.next56 return57 else:58 if self.next != None:59 self.next.delete(v)60 if self.next.value == None:61 self.next = None62 return63 def display(self):64 if self.isempty()==True:65 print('None')66 else:67 temp = self68 while temp!=None:69 print(temp.value,end=" ")70 temp = temp.next71head = Node(10)72head.append(20)73head.append(30)74head.appendi(40)75head.appendi(50)76head.delete(30)77head.display()
Code Execution Flow
Using two classes
xxxxxxxxxx631class Node:2 def __init__(self, data):3 self.data = data4 self.next = None5
6class LinkedList:7 def __init__(self):8 self.head = None9 def isempty(self):10 if self.head == None: 11 return True12 else:13 return False14 def append(self,data):15 # If list is empty16 if self.isempty():17 self.head=Node(data)18 else:19 temp = self.head20 # Traverse the list to find the last node21 while temp.next != None:22 temp = temp.next23 temp.next = Node(data)24 def delete(self,v):25 # If list is empty26 if self.isempty() == True:27 return 'List is empty'28 # If list have only one element and equal to v29 elif self.head.next == None:30 # If v is the first node of the list31 if self.head.data == v: 32 self.head = None33 else:34 return 'Not exist'35 else:36 temp = self.head37 temp1 = self.head38 # Traverse the list to find node with v value39 while temp.next!= None and temp.data != v: 40 temp1 = temp41 temp = temp.next42 # If v is the first node of the list43 if temp.data == v and temp == self.head: 44 self.head = temp.next45 # If v is the any node of the list except the first node46 elif temp.data == v: 47 temp1.next= temp.next48 else:49 return 'Not exist'50 def display(self):51 if self.isempty()==True:52 print('None')53 else:54 temp = self.head55 while temp!=None:56 print(temp.data,end=" ")57 temp = temp.next58L = LinkedList()59L.append(30)60L.append(40)61L.append(50)62L.delete(30)63L.display()
Code Execution Flow
Advantage
Insertion and deletion operations are easy
Many complex applications can be easily carried out with linked list concepts like tree, graph, etc.
Disadvantage
More memory required to store data
Random access is not possible
Application
Implementation stack, queue, deque
Representation of graph.
Representation of sparse matrix
Manipulation of the polynomial expression
Stack
A Stack is a non-primitive linear data structure. It is an ordered list in which the addition of a new data item and deletion of an already existing data item can be done from only one end, known as top of the stack.
The last added element will be the first to be removed from the Stack. That is the reason why stack is also called Last In First Out (LIFO) type of data structure.
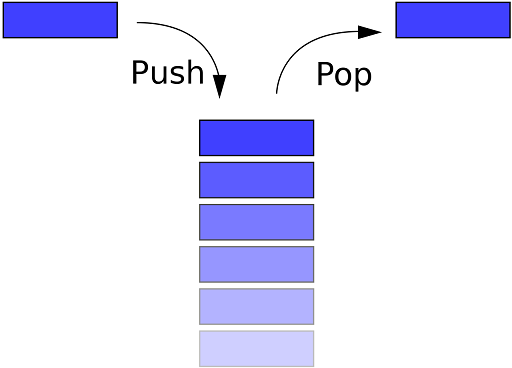
Basic operations on Stack
Push
The process of adding a new element to the top of the Stack is called the Push operation.
Pop
The process of deleting an existing element from the top of the Stack is called the Pop operation. It returns the deleted value.
Traverse/Display
The process of accessing or reading each element from top to bottom in Stack is called the Traverse operation.
Applications of Stack
Reverse the string
Evaluate Expression
Undo/Redo Operation
Backtracking
Depth First Search(DFS) in Graph(Will be discussed in Week-4)
Implementation of the Stack in Python
Stack implementation using a python list
xxxxxxxxxx221class Stack:2 def __init__(self):3 self.stack = []4 def isempty(self):5 return(self.stack == [])6 def Push(self,v):7 self.stack.append(v)8 def Pop(self):9 v = None10 if not self.isempty():11 v = self.stack.pop()12 return v 13 def __str__(self):14 return(str(self.stack))15S = Stack()16S.Push(10)17S.Push(20)18S.Push(30)19S.Push(40)20print(S.Pop())21print(S.Pop())22print(S)
Code Execution Flow
Stack implementation using a Linked list
xxxxxxxxxx501class Node:2 def __init__(self, data):3 self.data = data4 self.next = None5
6class Stack:7 def __init__(self):8 self.top = None9 10 def isempty(self):11 if self.top == None: 12 return True13 else:14 return False15
16 def Push(self,data):17 if self.isempty():18 self.top = Node(data)19 else:20 temp = Node(data)21 temp.next = self.top22 self.top = temp23
24 def Pop(self):25 if self.isempty() == True:26 return None27 else:28 temp = self.top.data29 self.top = self.top.next30 return temp31
32 def display(self):33 if self.isempty()==True:34 return None35 else:36 temp = self.top37 while temp != None:38 print(temp.data)39 temp = temp.next 40
41
42S = Stack()43S.Push(30)44S.Push(40)45S.Push(50)46S.Push(60)47S.Push(70)48print(S.Pop())49print(S.Pop())50S.display()
Code Execution Flow
Queue
The Queue is a non-primitive linear data structure. It is an ordered collection of elements in which new elements are added at one end called the Back end, and the existing element is deleted from the other end called the Front end.
A Queue is logically called a First In First Out (FIFO) type of data structure.
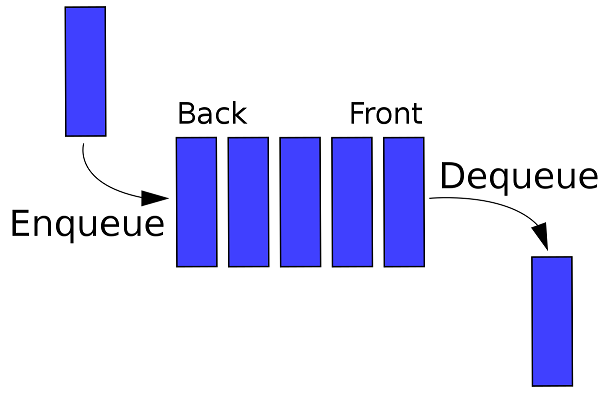
Basic operations on Queue
Enqueue
The process of adding a new element at the Back end of Queue is called the Enqueue operation.
Dequeue
The process of deleting an existing element from the Front of the Queue is called the Dequeue operation. It returns the deleted value.
Traverse/Display
The process of accessing or reading each element from Front to Back of the Queue is called the Traverse operation.
Applications of Queue
Spooling in printers
Job Scheduling in OS
Waiting list application
Breadth First Search(BFS) in Graph(Will be discussed in Week-4)
Implementation of the Queue in python
Queue implementation using a python list
xxxxxxxxxx241class Queue:2 def __init__(self):3 self.queue = []4 def isempty(self):5 return(self.queue == []) 6 def enqueue(self,v):7 self.queue.append(v) 8 def dequeue(self):9 v = None10 if not self.isempty():11 v = self.queue[0]12 self.queue = self.queue[1:]13 return v 14 def __str__(self):15 return(str(self.queue))16
17Q = Queue()18Q.enqueue(10)19Q.enqueue(20)20Q.enqueue(30)21Q.enqueue(40)22print(Q.dequeue())23print(Q.dequeue())24print(Q)
Code Execution Flow
Queue implementation using a Linked list
xxxxxxxxxx601class Node:2 def __init__(self, data):3 self.data = data4 self.next = None5
6class Queue:7 def __init__(self):8 self.front = None9 self.rear = None10 11 def isempty(self):12 if self.front == None: 13 return True14 else:15 return False16
17 def Enqueue(self,data):18 if self.isempty():19 self.front = Node(data)20 self.rear = self.front21 else:22 temp = Node(data)23 self.rear.next = temp24 self.rear = temp25
26 def Dequeue(self):27 if self.isempty() == True:28 return None29 elif self.front.next == None:30 temp = self.front.data31 self.front = None32 self.rear = None 33 else:34 temp = self.front.data35 self.front = self.front.next36 return temp37
38 def display(self):39 if self.isempty()==True:40 print(None)41 else:42 temp = self.front43 while temp != None:44 print(temp.data)45 temp = temp.next 46
47
48Q = Queue()49Q.Enqueue(30)50Q.Enqueue(40)51Q.Enqueue(50)52Q.Enqueue(60)53Q.Enqueue(70)54print(Q.Dequeue())55print(Q.Dequeue())56print(Q.Dequeue())57print(Q.Dequeue())58print(Q.Dequeue())59print(Q.Dequeue())60Q.display()
Code Execution Flow
Hash mapping
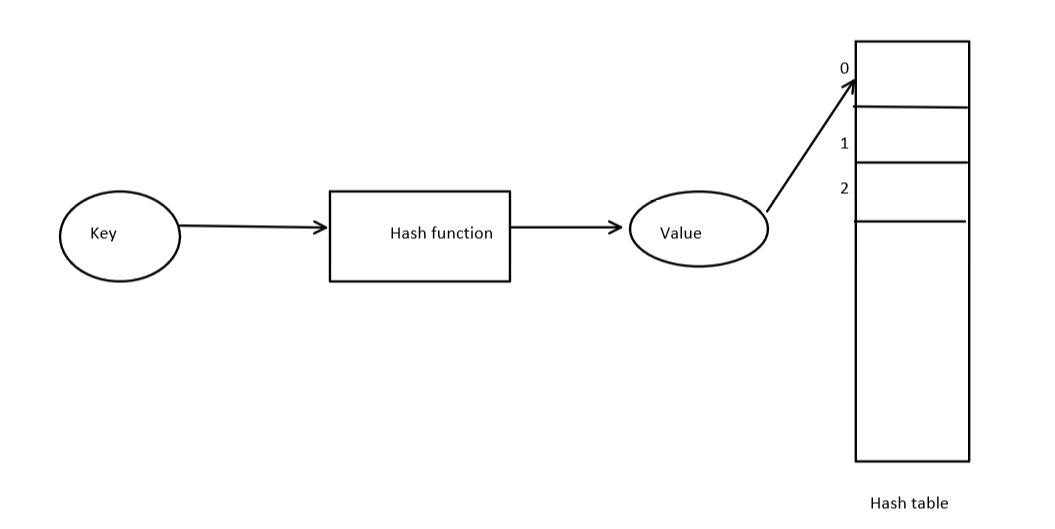
Hash mapping, also known as hash table or dictionary, is a data structure that allows for efficient insertion, deletion, and retrieval of key-value pairs.
The basic idea behind hash mapping is to use a hash function to map the key to a bucket in an array. The hash function takes the key as input and returns an index of the array where the value corresponding to the key can be stored. When we want to retrieve a value, we simply use the hash function to calculate the index and then access the value stored at that index.
One of the advantages of hash mapping is its constant-time complexity for basic operations such as insertion, deletion, and retrieval, on average, making it efficient for large datasets. However, the performance can be affected by factors such as the quality of the hash function, the number of collisions (i.e., when multiple keys map to the same index), and the size of the array.
For storing element
For searching element
Collision
The situation where a newly inserted key maps to an already occupied slot in the hash table is called collision.
Collision resolving technique
Open addressing(Close hashing)
Linear probing is an open addressing scheme in computer programming for resolving hash collisions in hash tables. Linear probing operates by taking the original hash index and adding successive values linearly until a free slot is found.
An example sequence of linear probing is:
h(k)+0, h(k)+1, h(k)+2, h(k)+3 .... h(k)+m-1where
mis a size of hash table, andh(k)is the hash function.Hash function
Let
h(k) = k mod mbe a hash function that maps an elementkto an integer in [0, m−1], where m is the size of the table. Let theith probe position for a valuekbe given by the functionh'(k,i) = (h(k) + i) mod mThe value of
i = 0, 1, . . ., m – 1. So we start fromi = 0, and increase this until we get a free block in hash table.Quadratic probing is an open addressing scheme in computer programming for resolving hash collisions in hash tables. Quadratic probing operates by taking the original hash index and adding successive values of an arbitrary quadratic polynomial until an open or empty slot is found.
An example of a sequence using quadratic probing is:
Quadratic function
Let
h(k) = k mod mbe a hash function that maps an elementkto an integer in [0, m−1], where m is the size of the table. Let thewhere
c1 and c2are positive integers. The value ofi = 0, 1, . . ., m – 1. So we start fromi = 0, and increase this until we get one free slot in hash table.
Closed addressing ( Open hashing)
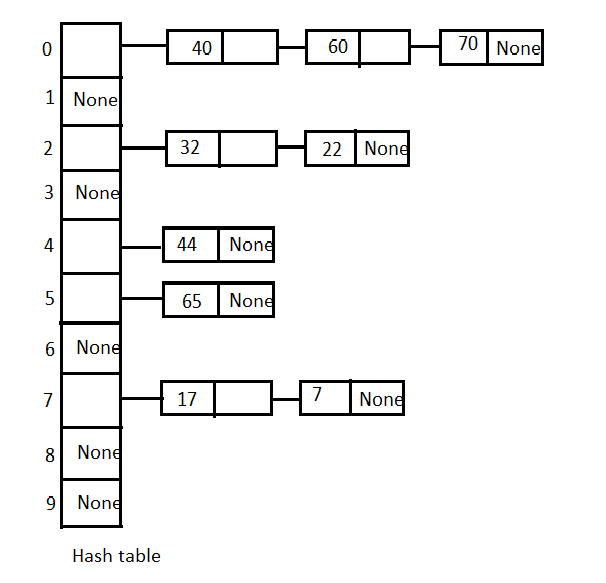
Separate chaining using linked list: Maintain the separate linked list for each possible generated index by the hash function.
For example, if the hash function is
k mod 10where k is the key and 10 is the size of the hash table.
Visualization of Hashing
Source - https://visualgo.net/en/hashtable